Directory structures for import
Import in this context is understood to subsume these use cases:
-
importing new content (operation “archive”)
-
updating existing content and attributes (operation “update”)
-
updating only attributes (see chapter Bulk attribute update)
-
example which is not supported: document batch – 0815
-
example which is supported: document batch-0815
Beneath the batch directory level, several variants are possible regarding the folder structure. The following directory types are supported by FIS:
-
transactions (directory with default suffix “.tra”)
-
sections (directory with default suffix “.sec”)
Whereas transactions provide different means of handling error situations, sections are merely a workaround for handling large quantities of files in a file system.
Documents within a transaction are imported by one transaction in a database-like manner, i.e. either all documents from a transaction directory will be imported or none, if an error occurs.
Due to technical restrictions a file system can only allow a certain maximum number of subdirectories within one directory. Sections provide a workaround by fragmenting the input directories into several section folders. E.g. if there are 5000 section folders and each of them has 5000 document folders, 25 million documents in a batch folder are possible.
Supported directory structure variants
The following kinds of directory structures are possible for import.
-
batch with sections
-
batch with transactions
-
batch with sections and transactions
-
flat batch
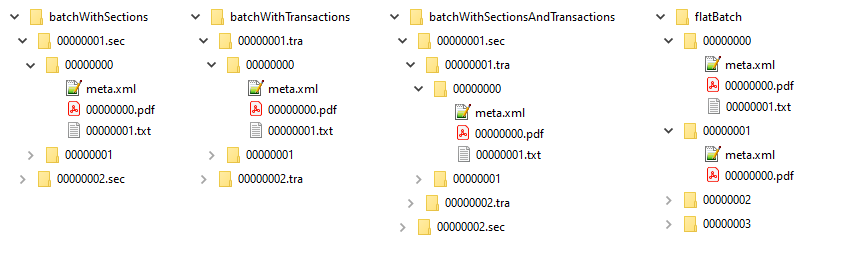
Figure 478: Supported directory structures for import
An overview of the directory types and file types from a directory structure, which is appropriate for FIS, is presented in the following table:
|
Element |
Description |
|---|---|
|
Directories |
|
|
batch directory |
Batch directories are folders, where each folder specifies one batch job. The batch directory contains all binary files and metadata needed for a FIS run (varying in detail depending on the operation to be executed, i.e. import or export). The names of batch directories are arbitrary. |
|
transaction directory |
This is an optional folder with extension ‘.tra’. See Transactions. |
|
section directory |
An optional folder with extension ‘.sec’ specifies a section in one job. The names of these directories are arbitrary. See Sections. |
|
document directory |
A folder represents one document, which contains all binary data files with corresponding metadata (meta.xml). The names of these directories can freely be chosen. |
|
Input Files |
|
|
binary data file |
The binary data files represent the actual contents of documents. These files may have their original filename or, if impossible, to use the name in the file system (e.g. due to certain special characters which may not be allowed), a temporary artificial filename may be used. Both names can be handled in the meta.xml file. The names of these files are arbitrary. |
|
metadata file “meta.xml” |
This xml file contains all necessary metadata for archiving one document. It must be located in the lowest level directory together with the belonging binary data file. |
|
Protocol Files |
A backup location may be configured (see parameter “p” in appendix Command line commands and parameters). |
|
SUCCESS.*.prot |
This is the success protocol file. It contains information on which documents have been archived. |
|
ERROR.*.prot |
This is the error protocol file. It contains information on which documents have NOT been archived and it tells details about the errors which have occurred. |
|
STATE.*.prot |
This is the state protocol file containing the current process state (periodically updated) and after the run has terminated it will contain the end state of the process. |
Also see the section on specific directory scenarios (chapter FIS behavior in specific scenarios) for further details on FIS behavior.