The following configuration settings can be adjusted by the ImageMaster AdminClient. This documentation only presents a brief overview. For related details see section Fulltext configuration in the corresponding user manual [UM AdminClient].
Connection settings
The following connection settings are mandatory for an ImageMaster full-text configuration:
-
URL of the indexing server
-
URL of the search server
In a simple environment both of these URLs will point to one Solr core. The URL must point to the corresponding Solr home:
http://YourSolrHost:8983/solr/master
In a complex environment, performance requirements may dictate a search architecture with multiple Solr servers, each one with a specific role. Besides configuring two different URLs, one for indexing (master) and one for search (slave), the configuration therefore also allows defining multiple URLs for each server type (i.e. multiple URL entries for indexing servers and multiple URL entries for search servers).
Indexing scope
The AdminClient allows you to define which ImageMaster document types and which MIME types are targeted by full-text indexing. A list of allowed MIME types is shown below. It is possible to configure only a subset from this list:
-
application/msexcel
-
application/mspowerpoint
-
application/msword
-
application/pdf
-
application/x-tar
-
application/zip
-
application/vnd.ms-excel.sheet.binary.macroEnabled.12
-
application/vnd.ms-outlook
-
application/vnd.openxmlformats-officedocument.presentationml.slideshow
-
application/vnd.openxmlformats-officedocument.presentationml.template
-
application/vnd.openxmlformats-officedocument.presentationml.presentation
-
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
-
application/vnd.openxmlformats-officedocument.spreadsheetml.template
-
application/vnd.openxmlformats-officedocument.wordprocessingml.document
-
application/vnd.openxmlformats-officedocument.wordprocessingml.template
-
text/csv
-
text/html
-
text/plain
-
text/richtext
-
text/rtf
For detailed instructions on how to disable full-text indexing based on ImageMaster document type or MIME type, see the user manual [UM AdminClient].
Basic tuning
Following basic tuning parameters can be adjusted by the ImageMaster AdminClient:
-
queue size for documents waiting for full-text indexing
-
number of documents to be streamed in parallel to the indexing server
Internal configuration management and customization
The configuration for ImageMaster full-text indexing is managed in an internal system document. The figure below illustrates a sample creation request for such a document as it may originate from the ImageMaster AdminClient or the ImaAdmin Web service.
Beside the configuration settings from above, further settings are customizable via this document type. However, such a customization must always be worked out depending on project specific requirements. As a starting point also see section Indexing – schema.xml.
<?xml version="1.0" encoding="UTF-8"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2003/05/soap-envelope"
xmlns:ns="http://www.tsystems.com/ima9/integrationws/messaging/201101">
<soap:Header>
<role:role xmlns:role= "http://www.tsystems.com/ima/9.0/integrationws/header/roles">powerUser</role:role>
</soap:Header>
<soap:Body>
<ns:createDocument>
<revision>
<documentType name="_COMMONS_CONFIGURATION"/>
<metadata>
<attribute name="_COMMONS_CONFIGURATION_CONFIGURATION_NAME">SearchConnectorConfiguration
</attribute>
<attribute name="_COMMONS_CONFIGURATION_CONFIGURATION">
<![CDATA[
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<ns3:searchConfiguration xmlns:ns2="http://www.unicode.org/ns/2003/ucd/1.0" xmlns:ns3="http://www.tsystems.com/ima/9.0/searchConfiguration">
<searchCommonProperties maxNumberOfSnippet="5">
<mimeTypes>text/plain</mimeTypes>
<mimeTypes>application/msexcel</mimeTypes>
<mimeTypes>application/msword</mimeTypes>
<documentTypes>internal_name_of_document_type_1</documentTypes>
<documentTypes>internal_name_of_document_type_2</documentTypes>
</searchCommonProperties>
<searchProviderProperties searchProviderName="Solr Search Provider">
<searchProperty name="masterUrls">
<values>http://127.0.0.1:8983/solr/master0</values>
<values>http://127.0.0.1:8983/solr/master1</values>
<values>http://127.0.0.1:8983/solr/master2</values>
<values>http://127.0.0.1:8983/solr/master3</values>
</searchProperty>
<searchProperty name="slaveUrls">
<values>http://127.0.0.1:8983/solr/slave0</values>
<values>http://127.0.0.1:8983/solr/slave1</values>
<values>http://127.0.0.1:8983/solr/slave2</values>
<values>http://127.0.0.1:8983/solr/slave3</values>
</searchProperty>
<searchProperty name="extractUrl">
<values>/imaupdate/extract</values>
</searchProperty>
<searchProperty name="searchUrl">
<values>/imasearch</values>
</searchProperty>
<searchProperty name="queueSize">
<values>20</values>
</searchProperty>
<searchProperty name="threadCount">
<values>4</values>
</searchProperty>
<searchProperty name="queryFields">
<values>fulltext</values>
<values>fulltext_de</values>
<values>fulltext_en</values>
<values>fulltext_fr</values>
<values>fulltext_es</values>
<values>unitedmetadata</values>
<values>unitedmetadata_de</values>
<values>unitedmetadata_en</values>
<values>unitedmetadata_fr</values>
<values>unitedmetadata_es</values>
</searchProperty>
<searchProperty name="phraseFields">
<values>fulltext_phrase</values>
<values>unitedmetadata_phrase</values>
</searchProperty>
<searchProperty name="wildcardFields">
<values>fulltext_phrase</values>
<values>unitedmetadata_phrase</values>
</searchProperty>
<searchProperty name="reindexUrl">
<values>http://127.0.0.1:8985/solr/master0</values>
</searchProperty>
</searchProviderProperties>
</ns3:searchConfiguration>
]]></attribute>
</metadata>
<contents/>
</revision>
</ns:createDocument>
</soap:Body>
</soap:Envelope>
|
Property |
Mandatory |
Description |
Example / Remark |
|---|---|---|---|
|
masterUrls |
Yes |
All master URLs The URLs depend on Solr configuration. |
127.0.0.1:8983/solr/master0 |
|
slaveUrls |
Yes |
All slave URLs The URLs depend on Solr configuration. |
127.0.0.1:8983/solr/slave0 |
|
extractUrl |
Yes |
The tail part of the index URL which is used as the underlying, internal Solr extracting request handler This parameter can be the suggested default value (see right column) in most scenarios. This parameter is either “/update/extract” if only one content object per revision is expected or “/imaupdate/extract” if more than one content object per revision is expected or if it is necessary to index files in compressed file formats like zip or tar. |
/update/extract or /imaupdate/extract |
|
searchUrl |
Yes |
The tail part of the search URL which is used as the underlying, internal search request handler This parameter is normally either “/” if only one slave URL exists or “/imasearch” if sharing over more than one slave URL is necessary. |
/ or /imasearch |
|
queueSize |
Yes |
The size of the queue of the streaming update server, i.e. the maximum number of documents which wait for full-text processing |
Recommended default value for a simple scenario: 20 |
|
threadCount |
Yes |
The number of threads the streaming update server is allowed to use |
Recommended default value for a simple scenario: 4 |
|
queryFields |
No |
An index field used both for binary files search (fulltext) and for attribute search (unitedmetadata) For multi-language support, use the corresponding language abbreviation: _en, _de etc. German (de), English (en), French (fr) and Spanish (es) have predefined field types and can be configured in the configuration file solrcore.properties. |
fulltext; fulltext_en; fulltext_de |
|
phraseFields |
Yes |
An index field used for phrase search If no specific phrase search is to be used, only “fulltext” and “unitedmetadata” can be specified. In this case, do not forget to adjust the provided schema.xml file. |
fulltext_phrase, unitedmetadata_phrase. |
|
wildcardFields |
Yes |
Index fields which are used during wildcard search in content objects |
You can use the same fields as in parameter phraseFields. |
|
No |
The URL of the instance used specifically for re-indexing (see Re-indexing with Solr instance migration) This URL is temporarily set in a migration scenario, where it represents the master URL of the new Solr instance that will be used later, after the re-indexing has been completed. |
127.0.0.1:8985/solr/master0 |
|
|
Table 341: Full-text search configuration parameters |
|||
Configuration of a full-text search result entry
The “document identifier” options, which can be set in the AdminClient, determine what content is displayed in a full-text search result entry. In the AdminClient go to Administration > Document Types > Attributes:
-
This option marks an attribute that should appear in the title of a full-text search result entry.
-
This option marks an attribute that should appear below the title of a full-text search result entry.
Below is an example with full-text search result entries, where each entry is structured like this:
-
a bold title at the top (based on the parts of the document identifier)
-
the ImageMaster document type
-
a summary (based on the parts of the document summary)
-
conditional: snippet with search term and context
The snippet is only displayed if the field which contains the hit is configured as a stored field in the Solr index.
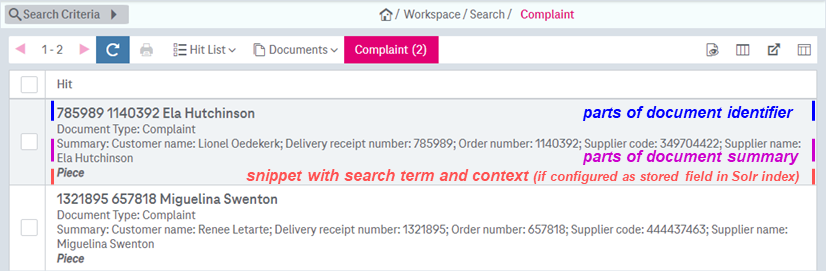
Figure 497: Text search result entries with title and summary
The document identifier options that you set in the AdminClient also determine how document titles appear elsewhere in the WorkplaceClient:
A document identifier can appear in several locations in the WorkplaceClient. For example, after selecting a document in the hit list, a document identifier is displayed in the top area (above the hit list). After having opened a document in the view “Documents”, this identifier is also used in the list of opened documents. In a full-text search, the document identifier is used as the title of a search result.