PREP-#Number#
|
Nr. |
Parameter |
Example |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
2000 |
JobMode_Prepare |
21 |
|||||||||
|
Sets the JobMode to be used in the Prepare step |
|||||||||||
|
2001
|
|||||||||||
|
This value represents a string of characters which is prepended to a filename during the Prepare step. The example value, which uses variables in turn, indicates that the current date with some configurable separator character is used. It is possible to use the current filenames via [INDEXFILE] and [DATAFILE], e.g.: <CurrentDate><SplittingChar>[DATAFILE]<SplittingChar> |
|||||||||||
|
2002
|
# |
||||||||||
|
A separator character that can be used in various contexts (like a comma or a semicolon in a CSV file). |
|||||||||||
|
2003 |
imagefile;SapBarcodeId;Creator |
||||||||||
|
|
There are different syntactical notations for this parameter. The first notation is suited for parsing from XML files without opening and closing tags, whereas the second one is suited for right this. Both variants can also be combined. These notations are explained below. |
||||||||||
|
|
Besides, an extended parameter notation is supported. See <PrepXMLDocTypeElement>. |
||||||||||
|
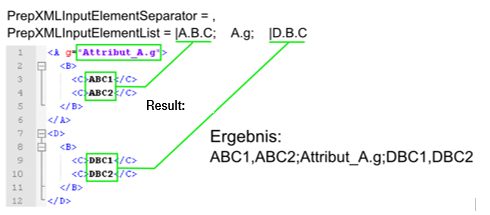
Variant 1: Use a list of semicolon-separated tags to search for. The order of the tags determines the order in the output file. A non-existing tag element raises an error unless the tag is marked as optional with a preceding asterisk. |
|||||||||||
|
To read a tag’s attribute value, refer to this value by separating tag name (TN) and attribute name (AN) via a dot, e.g. “TN.AN”. To read a tag's text content (TC), refer to this text by separating tag name (TN) and attribute name (AN) via a dot and append the attribute value (AV) in curly brackets , e.g. "TN.AN{AV}". If the tag name is preceded by a namespace (NS), the separator “:” must be replaced by the placeholder [DOPPELPUNKT], otherwise the parser would incorrectly assume syntax variant 2. So, in this case instead of “NS:TN.AN” use the appropriate notation: NS[DOPPELPUNKT]TN.AN |
|||||||||||
|
|
If multiple occurrences of an element are possible, signal this with a pipe symbol |. The values in their output will then be separated by <PrepXMLInputElementSeparator>. An optional field with multiple occurrences is marked by the pipe followed by an asterisk |*. |
||||||||||

|
|||||||||||
|
|||||||||||
|
Variant 2: Use a query syntax to navigate to the relevant tags. The values of these tags are written into a CSV file separated by the character <SplittingChar>. The following queries illustrated below the figure are possible:
|
|||||||||||
|
|||||||||||
|
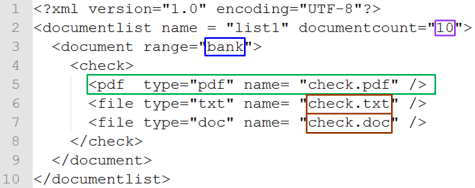
|
Returns the value of the attribute of the element. It must be ensured that the element is unique, e.g. by using [tree]. According to the above example: document:range returns bank |
||||||||||
|
|||||||||||
|
|
|
||||||||||
|
|
|
||||||||||
|
2004
|
, |
||||||||||
|
If an element was specified via <PrepXMLInputElementList>, which starts with the pipe symbol “|”, multiple occurrences are returned separated by the character given here. |
|||||||||||
|
2005
|
_ |
||||||||||
|
If this separator character is given, the filename of the input file is parsed and according values are returned. If the filename is “Company1_27.6.2007_092138732894.txt”, for example, and the separator is an underscore “_”, three values are extracted: “Company1”, “27.6.2007” and “092138732894”. |
|||||||||||
|
2006
|
Stammdaten.csv |
||||||||||
|
In JobMode 23 the filename given here is interpreted as the relevant master data which belongs to this job. |
|||||||||||
|
2007
|
<ColdConfigDirectory>/check.bpochecker.ini |
||||||||||
|
In JobMode 90 an additional configuration file is needed, which contains settings that are only relevant for this JobMode. |
|||||||||||
|
2008 |
ID<SpoolType><Generation>[YEAR][FILE][DOCNR] |
||||||||||
|
|
With this option a unique barcode can be generated and added to the data. The format is freely definable via the following variables: |
||||||||||
|
|
[YEAR] |
The current year, e.g. 2017 |
|||||||||
|
|
[MONTH] |
The current month as a number, e.g. 12 for December (01-12) |
|||||||||
|
|
[DAY] |
The day of the month as a number, e.g. 31 (01-31) |
|||||||||
|
|
[HOUR] |
The hour of the processing time (00-24) |
|||||||||
|
|
[MIN] |
The minute of the processing time (00-59) |
|||||||||
|
|
[SEC] |
The second of the processing time (00-59) |
|||||||||
|
|
[FILE] |
The filename without its extension |
|||||||||
|
|
[DOCNR] |
A (sequential) document number in the current generation |
|||||||||
|
|
[DOCNR:8] |
A document number of 8 digits padded with leading zeroes |
|||||||||
|
|
[SUBDOCNR] |
A document number in a subfolder of multiple batches |
|||||||||
|
|
[SUBDOCNR:10] |
Like SUBDOCNR with ten digits padded with leading zeroes |
|||||||||
|
|
<PID> |
The current process ID of the process |
|||||||||
|
|
<CurrentTimestamp> |
The number of seconds since 1970 |
|||||||||
|
2009
|
push(@item, $item[3] . $item[5] ); |
||||||||||
|
This option manipulates or adds single data values based on Perl code. The value must be a valid Perl command operating on the variable “@item”. This can be useful if one data field shall contain a combination of multiple other fields or if its content must be cut. Examples:
|
|||||||||||
|
2010
|
Index_ |
||||||||||
|
An indexing file is identified based on this prefix. |
|||||||||||
|
2011
|
<ColdBinDirectory>/pdfPageCount [FILE] |
||||||||||
|
With this parameter an external program can be executed, for example to determine the number of pages. The first row of output is added as a data value. If the internal tool “TiffPageCount” is used, awk must additionally be applied to filter the filename from this tool’s output as illustrated below: <ColdBinDirectory>/TiffPageCount [FILE] | |
|||||||||||
|
2012
|
0 |
||||||||||
|
This value specifies the column number which indicates the new filename of a content file. With the value 0 the mechanism is deactivated. If the value is 3, and in the indexing file the third value is “invoice.pdf” a file is searched for that ends with “invoice.pdf”, which is then renamed into “invoice.pdf”. This option is useful in JobMode 31, which is based on constant prefixes. |
|||||||||||
|
2013
|
No |
||||||||||
|
If this parameter is set to “Yes”, the character set conversion tool “iconv” is run, which must be located in the system path. This is useful if the incoming indexing files must be converted e.g. from UTF-8 to ISO8859-1. |
|||||||||||
|
2014
|
PrepConvertFrom |
UTF-8 |
|||||||||
|
If <PrepConvertIndexFiles> is set to “Yes”, this parameter defines the source encoding of the incoming data. Supported encodings can be listed with “iconv –l”. |
|||||||||||
|
2015
|
PrepConvertTo |
ISO8859-1 |
|||||||||
|
If <PrepConvertIndexFiles> is set to “Yes”, this parameter defines the target encoding of the conversion output. Supported encodings can be listed with “iconv –l”. |
|||||||||||
|
2016
|
<ColdBinDirectory>/specialPrepare.pl [FILE] [OUTFILE] |
||||||||||
|
The command given with this parameter is applied to each indexing file in JobMode 45. The following variables can be used, also with multiple occurrences:
|
|||||||||||
|
2017
|
RetryFlagFilename |
retry.flag |
|||||||||
|
In JobMode 80 it can happen that the step Prepare must be started many times. A file with the name given here is generated in the spool directory to indicate that another start was undertaken after a first attempt. |
|||||||||||
|
2018
|
ErrorFlagFilename |
ML001.LI1.<Generation>.error |
|||||||||
|
In the Prepare step in JobMode 80 errors are signaled via a file. The filename can be specified with this parameter. |
|||||||||||
|
2019
|
EndFlagFilename |
ML001.LI1.<Generation>.end |
|||||||||
|
In the Prepare step in JobMode 80 errors are signaled via a file. The finalization of writing this error file is indicated via another file with the name that can be specified with this parameter. |
|||||||||||
|
2020
|
RecordCheckLine |
0 |
|||||||||
|
This parameter indicates which row represents a checksum that reflects the number of input records. With 0 the mechanism is deactivated. A negative value can be used to count backwards from the ending, so “-1” indicates the last row. The exact structure of the checksum is defined by the parameter <RecordCheckRegEx>. |
|||||||||||
|
2021
|
([0-9]+);1\.0 |
||||||||||
|
This parameter defines the structure of the checksum based on a regular expression. The number of records must be put in brackets. The given example value filters any integer number which precedes the constant character string “;1.0”, e.g. the value “140” below:
|
|||||||||||
|
2022
|
0 |
||||||||||
|
If <PrepSearchSubdirectories> is active, this column is interpreted as a path to extend the names of delivered files by a subdirectory prefix. This is useful to check already in the Prepare step if an associated content file is present in a subdirectory. The value 0 deactivates the mechanism. If this parameter is used in the according Prepare JobMode, and its value is not 0, then the parameter <DataFileExtension> is ignored, as the content filenames are already fully specified via this parameter. (This parameter is similar to the parameter <FileField > in the Splitting step.) |
|||||||||||
|
2023
|
<ColdDataDirectory>/error/<SpoolType> |
||||||||||
|
If pre-processing requires signaling feedback to another process via a file, this directory is used for such files. |
|||||||||||
|
2024
|
jpg |
||||||||||
|
If a spool directory contains multiple file types, but only one type is supposed to be processed, this parameter can be used as a filter. Many file types can be given separated by a blank. |
|||||||||||
|
2025
|
PrepMultiDataFileExtensions |
pdf html |
|||||||||
|
This parameter is similar to <DataFileExtension> but used in JobModes where the content file extensions can change, e.g. by an uncompress operation where different file types can be present in a zipped file. The JobMode identifies all content files based on this, and usually there are also indexing files present with the same filename but a different file type extension. In some JobModes it is possible to use multiple file type extensions separated by blanks (e.g. PrepMultiDataFileExtensions = TIF PDF tif pdf). |
|||||||||||
|
2026
|
Idx |
||||||||||
|
This parameter is similar to <IndexFileExtension> but used in JobModes where the indexing file extensions can change, e.g. by an uncompress operation where different file types can be present in a zipped file. The JobMode identifies all indexing files based on this. |
|||||||||||
|
2027
|
<ColdLoggingDirectory>/ProtocolHelpFile.log |
||||||||||
|
In the Protocol JobMode 10 this file is used to signal the success status of archived documents. The file contains a mapping of a unique index value to an indexing file and its directory. Thus, the index values require a unique ID which is given by <PrepUniqueIndexForProtocol>. |
|||||||||||
|
2028
|
PrepUniqueIndexForProtocol |
7 |
|||||||||
|
Via this parameter the column is specified which contains the unique index value that is written into the file <PrepProtocolHelperFile> to ensure that there is a clear reference to a belonging indexing file in a log. The value 1 indicates the first record in the indexing file. |
|||||||||||
|
2029
|
document |
||||||||||
|
Several documents can be referenced in an XML structure. Via this parameter a surrounding parent element can be specified to treat those documents separately. Further elements to be parsed are given by <PrepXMLInputElementList>, but the parent element is <PrepXMLTopElement>. If this value is empty, it is assumed that there is only one document referenced in the XML. |
|||||||||||
|
Example : <spool>
<document>
<File>1.pdf</File>
</document>
<document>
<File>2.pdf</File>
</document>
</spool>
In this example the appropriate setting would be "PrepXMLTopElement = document". |
|||||||||||
|
2030
|
PrepSkipLinesFromStart |
0 |
|||||||||
|
Indicates how many rows in the beginning of the input file are ignored in the Prepare step. These rows are ignored in all input files, which can be useful if there is some kind of header data which is otherwise irrelevant for pre-processing in this step. |
|||||||||||
|
2031
|
PrepSkipLinesFromEnd |
0 |
|||||||||
|
Indicates how many rows in the ending of the input file are ignored in the Prepare step. These rows are ignored in all input files. This can be useful if there is some kind of status information in the ending, such as the number of records in the file. |
|||||||||||
|
2032 |
PrepRemoveDuplicateInputLines |
No |
|||||||||
|
|
If this option is set to “Yes”, the incoming files are analyzed and duplicate rows are removed. It is also possible to send an e-mail notification in this case via the next parameter. |
||||||||||
|
|
Be aware that the structure of the file changes in an unpredictable manner and you cannot be sure that a certain row still refers to the same document afterward!
|
||||||||||
|
2033
|
PrepDuplicateInputLinesEmail |
batch.processing.manager@t-systems.com |
|||||||||
|
This e-mail address is used for notifications if <PrepRemoveDuplicateInputLines> is set to “Yes”. Multiple recipients can be given with a blank as separator. |
|||||||||||
|
2034
|
PrepDuplicateInputLinesSubject |
Duplicate elements removed in <SpoolType.Generation> |
|||||||||
|
The subject of the notification e-mail in case of a duplicate removal can be set here. |
|||||||||||
|
2035
|
PrepFixedSplittingLengthCheck |
200 |
|||||||||
|
This parameter defines the expected length of a row in an input file. |
|||||||||||
|
2036
|
PrepFixedSplitting |
1-10,39-58,89-118,139-200 |
|||||||||
|
With this parameter ranges within one row can be specified which are used to extract data. This is useful if no separator characters are present but fixed positions are known instead. The first character in a row is at position 1. If a range from 39 to 58 is targeted at, use “39-58”. Multiple ranges can be separated by a comma. If only one character shall be extracted, it is necessary to define this as a range as well, e.g. “59-59”. To define all characters starting at a certain position and reaching to the end of the line (where the length does not matter) use a dollar sign, e.g. “60-$”. |
|||||||||||
|
2037
|
2 |
||||||||||
|
If this value is greater than 0, the referenced single column is treated as a filter column. Within this column a valid value must be given according to <PrepFixedSplittingValidCols>, otherwise this row is ignored. |
|||||||||||
|
2038
|
PrepFixedSplittingValidCols |
RECHDAT,RECHNR,RECHBETR |
|||||||||
|
With this parameter the allowed values of the filter column <PrepFixedSplittingFilterCol> are specified. Multiple values separated by a comma can be given. |
|||||||||||
|
2039
|
PrepFixedSplittingUseLastCol |
3 |
|||||||||
|
If this value is greater than 0 it is interpreted as a column where empty values are filled in a specific manner: If a delivered value in this column is empty, the previously found value for this column is used. For example, if a customer ID is not repeated on purpose, but it is still meant to be valid in further records, the latest valid customer ID can be referenced by this. |
|||||||||||
|
2040
|
PrepFixedSplittingModifyFilterCol |
Yes |
|||||||||
|
If this option is set to “Yes”, the value in the filter column <PrepFixedSplittingFilterCol> is preprocessed before writing it to the CSV file and all blanks and dots are removed. This is useful if this column is used as <SplittingDocTypeCol>. |
|||||||||||
|
2041
|
PrepXMLInputElementFileList |
Attachment:cryptname();Attachment:orgname() |
|||||||||
|
With this parameter a list of files can be extracted from an XML file in the indexing file. The parameter value must be formatted like <PrepXMLInputElementList>. If two elements are given, the first one determines the real, existing filename and the second one defines the newly desired filename. For example, if “cryptname” is to be renamed into “orgname”: PrepXMLInputElementFileList=Attachment:cryptname();Attachment:orgname() If no renaming is desired, only a single element must be given here. |
|||||||||||
|
2042
|
PrepAddFileIfExists |
Mitzeichnung.pdf |
|||||||||
|
If this file exists, it is added to the list of files. If it is missing, this is NOT interpreted as an error. |
|||||||||||
|
2043
|
PrepXMLInputElementListGlobal |
Document.Id |
|||||||||
|
This parameter can be used like <PrepXMLInputElementList>, but the values are resolved globally, so even if some top element is defined via <PrepXMLTopElement> it is possible to resolve values from outside of this top element scope. The given example “Document.Id” represents a query notation according to variant 2 of <PrepXMLInputElementList>: |
|||||||||||
|
2044
|
No |
||||||||||
|
If this option is set to “Yes”, the JobMode also searches in subdirectories (only used in JobMode 21 and 29). Also see <PrepFileNameColumn>. |
|||||||||||
|
2045
|
PrepChecksumTest |
MD5:8 |
|||||||||
|
Executes a checksum test (MD5 or Adler32) in JobMode 21. If this parameter is empty, no such test is run. There must be at most one belonging content file. Its name must either be like the one of the indexing file but with the data file extension <DataFileExtension> or it must be defined in column <PrepFileNameColumn>. Examples:
|
|||||||||||
|
2046
|
PrepFileSizeTest |
0 |
|||||||||
|
Executes a file size check in JobMode 21. With the value “0” no such check is run. There must be at most one belonging content file. Its name must either be like the one of the indexing file but with the data file extension <DataFileExtension> or it must be defined in column <PrepFileNameColumn>. Example:
|
|||||||||||
|
2047
|
PrepAddAllNonIdxFiles |
No |
|||||||||
|
If this parameter is set to “Yes”, in JobMode 21 all files which are located in the same directory as the indexing file are treated as content files [DATAFILE]. Consequently, via PrepAddConstantString=[DATAFILE] it is simply possible to add all these content files as documents. This is commonly used in combination with PrepSearchSubdirectories=Yes. |
|||||||||||
|
2048 |
PrepXMLSubSpecialCharsPath |
<ColdSpoolBaseDirectory>/<SpoolType>/ <SpoolType.Generation>/specialChar.txt |
|||||||||
|
|
This parameter specifies a name (with the path) of a file which contains a replacement mapping. In this file pairs consisting of some original character string and a new replacement string are given (original=new). If an index value contains one of the listed original character strings, these are substituted by the new replacement string. |
||||||||||
|
|
In the following example typical HTML special character encodings are replaced by their decoded characters: |
||||||||||
|
|
&=& "=" ä=ä Ä=Ä |
||||||||||
|
|
ö=ö Ö=Ö ü=ü Ü=Ü <=< >=> |
||||||||||
|
2049 |
Yes |
||||||||||
|
If this feature is used, a special syntax is expected for the parameter <PrepXMLInputElementList> where the document type must be appended, for example:
|
|||||||||||
|
2054 |
PrepRetryExternalCommandAllowed |
True |
|||||||||
|
In JobMode 96, the NONCRITICAL_ERROR exit code of the external command is forwarded to the Scheduler if this parameter is set to "True". Otherwise it is intercepted and replaced by the CRITICAL_ERROR exit code. The default is "True". This means that the external command can cause the Scheduler to retry if the parameter is "True". |
|||||||||||
|
2055 |
PrepFixCSVLineEnding |
No |
|||||||||
|
JobMode 29 ends each line of the created CSV file with a separator. This means that there is one value too many in each line. If this field is set to “Yes”, the line end is corrected. The default is “No” because of downward compatibility. |
|||||||||||
|
2057 |
PrepEmptyResultIsError |
No |
|||||||||
|
This parameter controls whether an empty result list should be considered as an error or not. Thereby the result list consists of the exported revision IDs during the legal export. This parameter is relevant for the legal export JobMode 951. |
|||||||||||
|
2058 |
PrepWriteEmptyResultReport |
Yes |
|||||||||
|
If this parameter is set, a <Docs>/NO-HITS/note.txt file is created in case of an empty export result list. This parameter is relevant for the legal export JobMode 952 . |
|||||||||||
|
2060 |
PrepFileNameMask |
ISREGEX;^Continental_[\d]{10}_[\d]{8}\.xml |
|||||||||
|
If this value is set, only files whose names match the mask are accepted as index files. The syntax is the same as for “FileNameMask”. |
|||||||||||
|
Table 94: Prepare configuration parameters |
|||||||||||